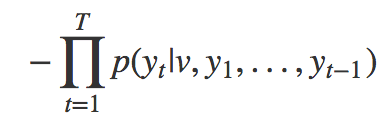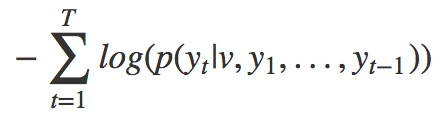Because back propagation gives us a generic learning algorithm, a large part of deep learning can be distilled down to the loss function used to represent the objective. Lets take a look at a few:
Generative Adversarial Networks

Loss Function:

Generative adversarial nets define an objective function that can be thought of as a minimax game. One agent (generative) tries to minimize the global function, while the other agent (discriminative) tries to maximize global function. Lets see what this would achieve:
Discriminator
First, lets look at the adversarial objective: to maximize the objective. Lets look at the first part of that equation:

Maximizing this means: Maximize the probability of data sampled from distribution p_data.
Looking at the second part of the loss function:

Maximizing this is equivalent to minimizing the D(G(z)). For the discriminator, this means: Minimize the probability of the output of G(z).
Combining the two terms, we can see that the discriminator is trying to maximize the probability of inputs sampled from real data, while trying to minimize the probability of data produced from G.
Generator
Now, lets analyze the objective of the generator, to minimize the overall objective. Since the generator has no handle on the first term, it can only minimize the objective via the second term.
Minimizing this equation is equivalent to maximizing the term D(G(z)). Essentially this means: Given an input sampled from p_z, maximize the probability of D. In order to do this, via G, the generator has to create inputs that fool the Discriminator to output a higher probability.
Here is a sample implementation that I hacked together to generate Pokemon images (it did not work as well as I hoped).
Neural Style Transfer

Loss Function:

Neural Style Transfer is a way of transferring the style of one image onto another by defining a “style loss” and a “content loss”. The final image is produced by trying to minimize the style loss and the content loss at the same time. That is, we want to minimize:
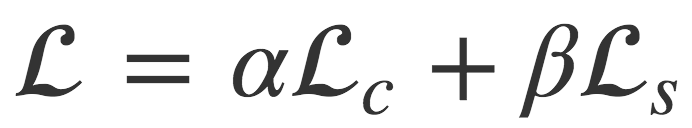
Lets consider the appropriate loss functions to represent a content loss and a style loss. The content loss proposed by Gatys et al. is to compute a Squared Error between the activations of the content image and the activations of the base image, passed through some pre-trained network (VGG16 for example) at some layer.
The style loss that is proposed by Gatys et al. is much more interesting than the content loss. Because we don’t care about the actual content of the style image, if we just took the loss against the outputs of a certain layer like we did with the content loss, we would end up creating an image that has similar content to both images, which results in this mess, where its essentially a mix of the content of Mona Lisa and Starry Night.

The problem here is that we have a spatially variant loss function, but “style” is spatially invariant. Intuitively what this means is that if we had a style image like this:

It should “look” the same to the loss function as:

These two images should look almost the same to our loss function since we only want to capture the style of the image, not the content.
The style loss function that is actually used in the paper is a Squared Error between the gram matrix of the activations of the style image and the base image. The reasoning behind this is that a gram matrix is spatially invariant, that is, the gram matrix of the activations of the starry night image, and the jumbled starry night image, will be approximately the same.
Sequence to Sequence Learning